In this post, we introduce the concept of Model Predictive Control (MPC), which originated as a mechanism for decision making in the 1960s in the petrochemical industry for complex process control with strict constraints. However, it has found wider applicability, especially in robotic systems, and is now touted as the 'System 2' for complex decision tasks. We begin with the fundamental idea behind MPC, how it is formulated mathematically and then move towards using it in a toy example: vertical landing of a rocket while using as little thrust as possible à la SpaceX. Along the way, we will see how prediction, optimization, and constraints come together to form a practical control strategy.
Brief history
In the 1960s and 70s, industrial processes such as those in oil refineries and petrochemical plants had grown too complex with little guarantees to be handled by traditional control methods. A system like a distillation column involved multiple inputs, including reflux rate, reboiler heat, and feed flow, all influencing multiple outputs such as product composition and temperature across different stages. These interactions were tightly coupled, the dynamics were slow, and the effects of any control action could take a long time to appear, all while the system had to operate within strict limits on temperature, pressure, and actuator capability. Engineers tried to manage this using independent PID loops, but these loops acted locally and without foresight, so correcting one variable often disturbed another, leading to oscillations and inefficient operation. At some point it became clear that reacting to the present was not enough, because every action had consequences that unfolded in the future. The question then shifted from what input should be applied now to what sequence of inputs should be applied over time. This change in thinking led to a new approach in which a model of the system is used to predict how it will evolve, an optimization problem is solved over a finite horizon to choose inputs that satisfy constraints and improve performance, and only the first input is applied before the process is repeated as new information becomes available. This idea, which came to be known as Model Predictive Control, was first implemented in the 1970s in forms such as Dynamic Matrix Control at Shell, where it proved valuable not because it was elegant, but because it worked under real constraints and improved economic performance.
Formulation
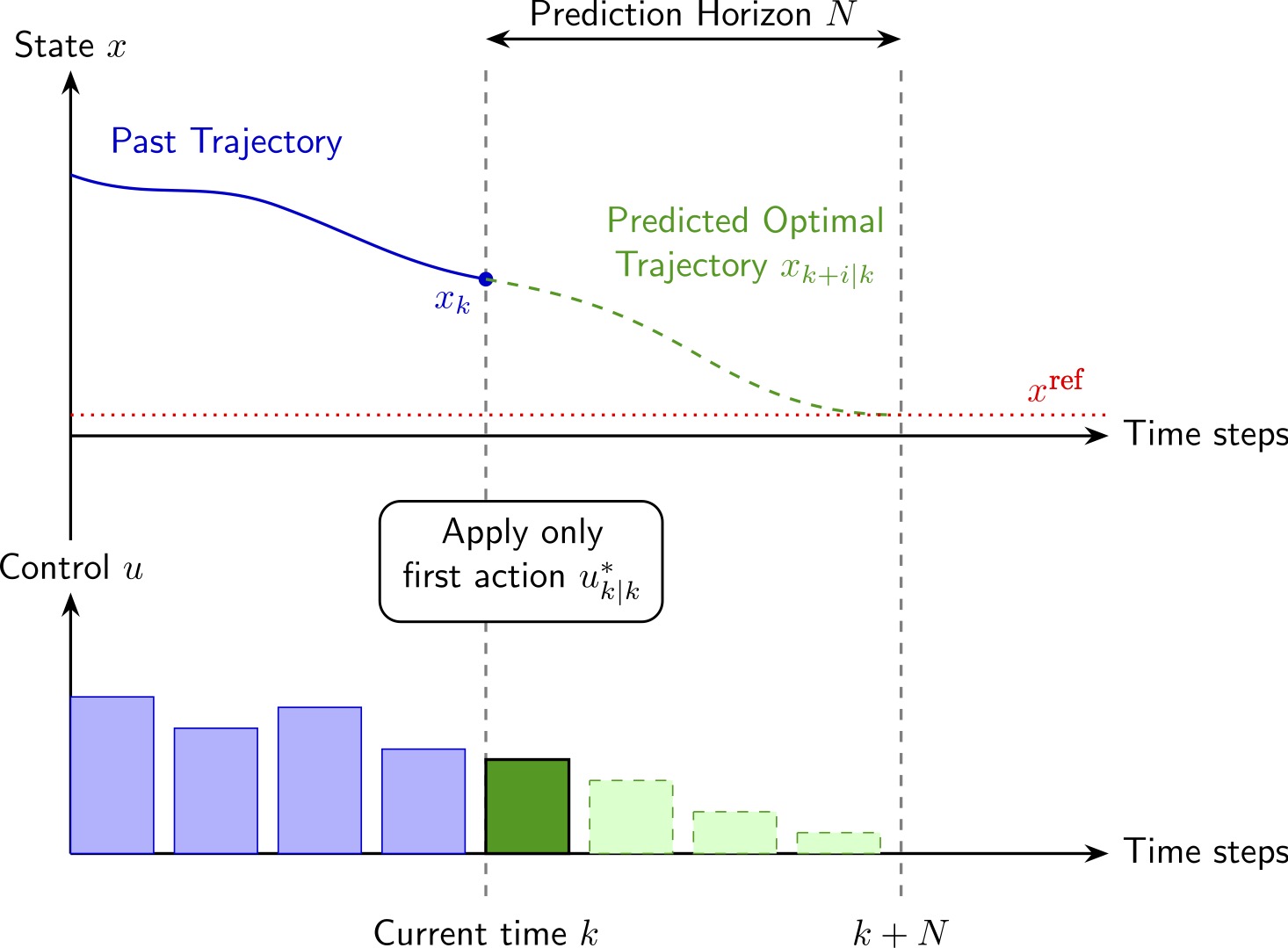
Schematic illustrating the MPC strategy. The top graph shows the past trajectory of the system resulting in the current state , alongside the predicted optimal trajectory approaching the target over the prediction horizon . The bottom graph displays the corresponding sequence of calculated control inputs. The fundamental idea behind MPC is to compute full future plan but apply only the immediate action .
Before we land anything, let us try to understand the mathematical formalism of MPC. Let us consider a system with state (could be the position or momentum or any variable that characterizes the system of interest) at a discrete time . The evolution of the state can be written as , where is the control input of the system and is the process that governs the dynamics of the system. Imagine riding a bicycle, the state describes where you are, how fast you are moving, and in what direction you are moving. The control input is the angle to which you rotate the handlebar or the thrust you provide on the pedal. Those actions determine where you will be in the next instant, which is the new state .
In the framework of Model Predictive Control, our goal is to decide what is the 'best' action to take at a particular instant by considering several future scenarios. That is, at time , we consider a sequence to choose the control input . The notation simply means "the control input at a future time , computed at time ". Once this future input sequence is fixed, the model tells us exactly what will happen next. Using the model , we can predict the next state, Using the same equation again, we can predict the state two steps ahead, The state several steps ahead, for , depends on the current state, and on all future control inputs, we have chosen. In other words, once we choose a future control input sequence , we have also chosen a future trajectory for the system. Control is not purely reactive, it is about shaping the future trajectory.
The obvious next question is: among all possible future input sequences , which one should we choose? To answer this, we introduce a cost function, . The cost function is a measure of how "good" a predicted future trajectory is with respect to how we want the system to behave. In the rocket landing example, we want the predicted height and velocity to approach zero over time. At the same time, we do not want to use unnecessarily large thrust. A simple way to express this is to penalize two quantities: the rocket's position error and the control effort. Over a horizon of future steps, we can define of the form:
In order to find the control input at time-step , our goal is to minimize for a fixed horizon . The optimization problem therefore consists of minimizing over the future input sequence, subject to the dynamic constraint . The first term in the cost function penalizes the deviation from the desired trajectory while the second penalizes excessive control action. Weighting factors adjust the relative importance of these two objectives. The predicted outputs depend on the chosen input sequence through the system dynamics. If the dynamics is linear and the cost is quadratic, the resulting optimization problem becomes a well known quadratic program. On the other hand, if the dynamics is nonlinear, the optimization becomes a nonlinear program. Therefore, the optimal sequence of inputs can be found by minimizing with respect to future inputs. The important aspect of MPC compared to other optimal control frameworks is that after computing this optimal control input at time-step , we do not apply it for all future times from to , rather we apply only the first control action, . At the next time-step, we measure the new state , shift the prediction horizon forward, and solve the optimization problem again. In this way, the control input is continuously re-evaluated based on updated state information. This repeated prediction and optimization is what makes Model Predictive Control adaptive.
In its most general form, a control problem consists of choosing an input sequence that minimizes a performance metric , subject to the system dynamics and physical constraints . For a discrete-time system, a finite-horizon optimal control problem can be written as
subject to
Here, represents the stage cost accumulated at each step and is the terminal cost. Model Predictive Control operates by repeatedly solving such a finite-horizon optimal control problem in real time. At each time-step, the problem is solved using the current state, as the initial condition, the first control action is applied, we shift the horizon ( steps) by one discrete time step to . In this sense, MPC is not a fundamentally different type of controller but rather a real-time implementation of optimal control. With this background in place, let us now try to land the rocket.
Landing the Rocket
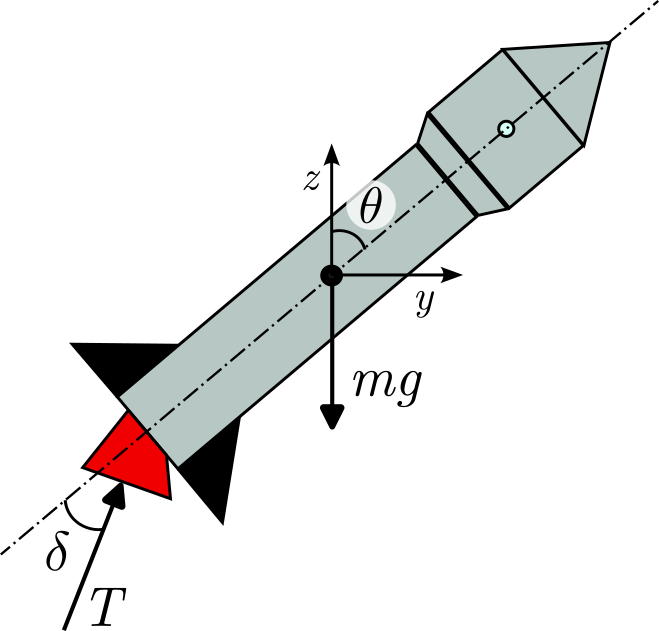
Schematic of the rocket in the -plane with its total mass (including fuel) , orientation and control variables, the gimbal angle and the thrust . The mass of the rocket evolves with time as the fuel gets consumed to exert thrust while the gimbal angle can be tuned to change the orientation of the rocket.
Consider the task of vertically landing a rocket which, as we shall see, is a concrete instance where we can use the general finite-horizon optimal control framework. Our goal is to plan the motion of a planar rigid rocket with variable mass whose state at time is given by
where and denote horizontal and vertical positions, is the pitch angle, , , and are the corresponding velocities, and is the current mass of the rocket. The control input is
where represents the thrust magnitude and the gimbal deflection angle, which are controlled through actuators. The rocket motion can then be described using Newton's laws for a variable mass rigid body. The thrust acts along the body axis of the rocket, while gravity acts downward (see figure above for a schematic of the setup). The translational dynamics is written as
The thrust exerted by the rocket, must reach zero when the fuel is empty. This effect is accounted for, while also maintaining the differentiability required by interior-point solvers, by approximating the hard engine cutoff using a smooth function. We define an activation function that smoothly transitions from to as the mass approaches ,
where is a steepness parameter that controls the sharpness of the cutoff. The effective thrust is then defined as the commanded thrust scaled by this activation factor, The mass depletion dynamics can be written as a single continuous equation, The translational dynamics driven by this effective thrust are given by
and the balance of torque about the center of mass yields the rotational dynamics,
These equations define a nonlinear continuous-time model . To use this model to perform the landing task using MPC, we need to discretize the temporal dynamics using a numerical scheme such as the 4-th order Runge Kutta scheme. This produces a discrete mapping given the current state and the control input . With the model in place, we now identify a cost function that measures performance. For soft landing, position, velocity, and orientation should approach zero near the landing pad. Using the discrete definition of the state, a reasonable choice of cost function is
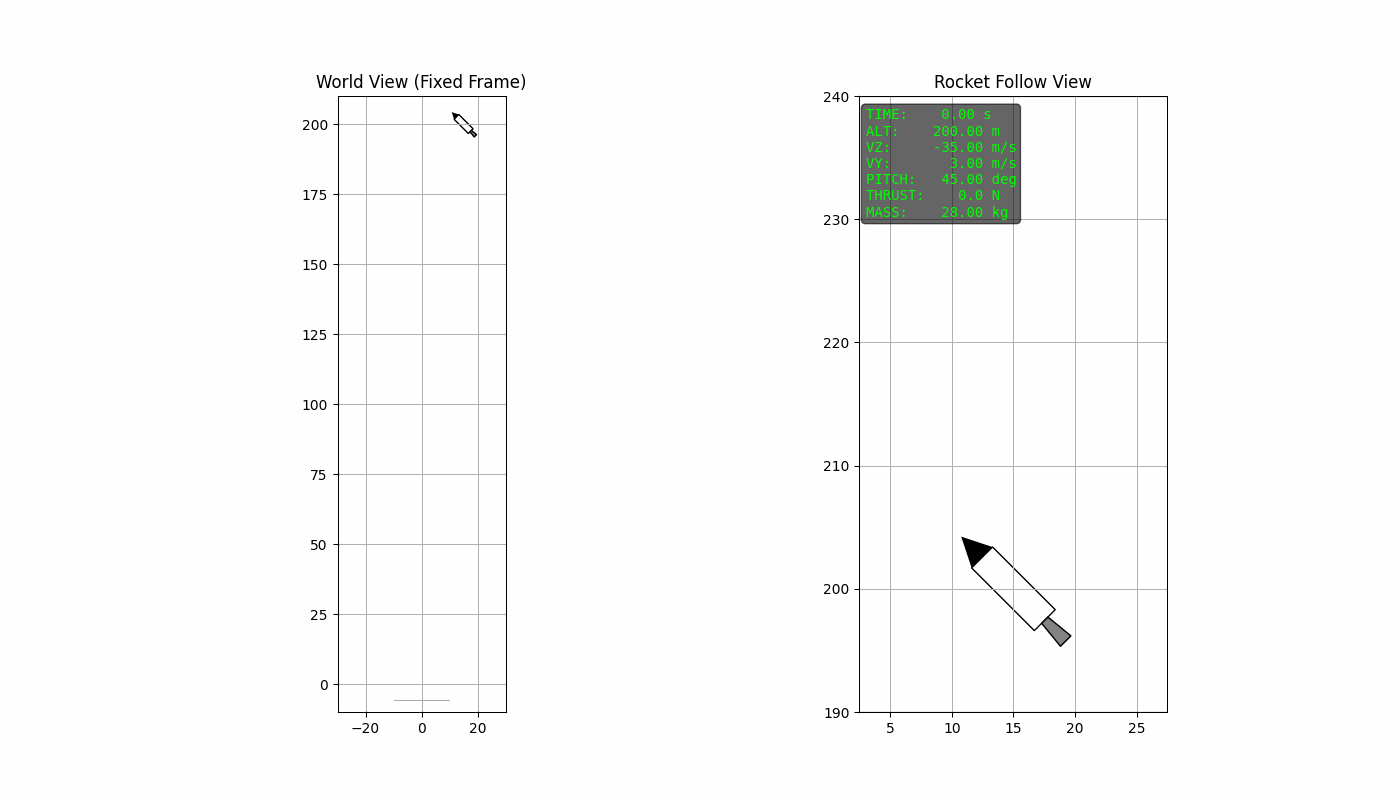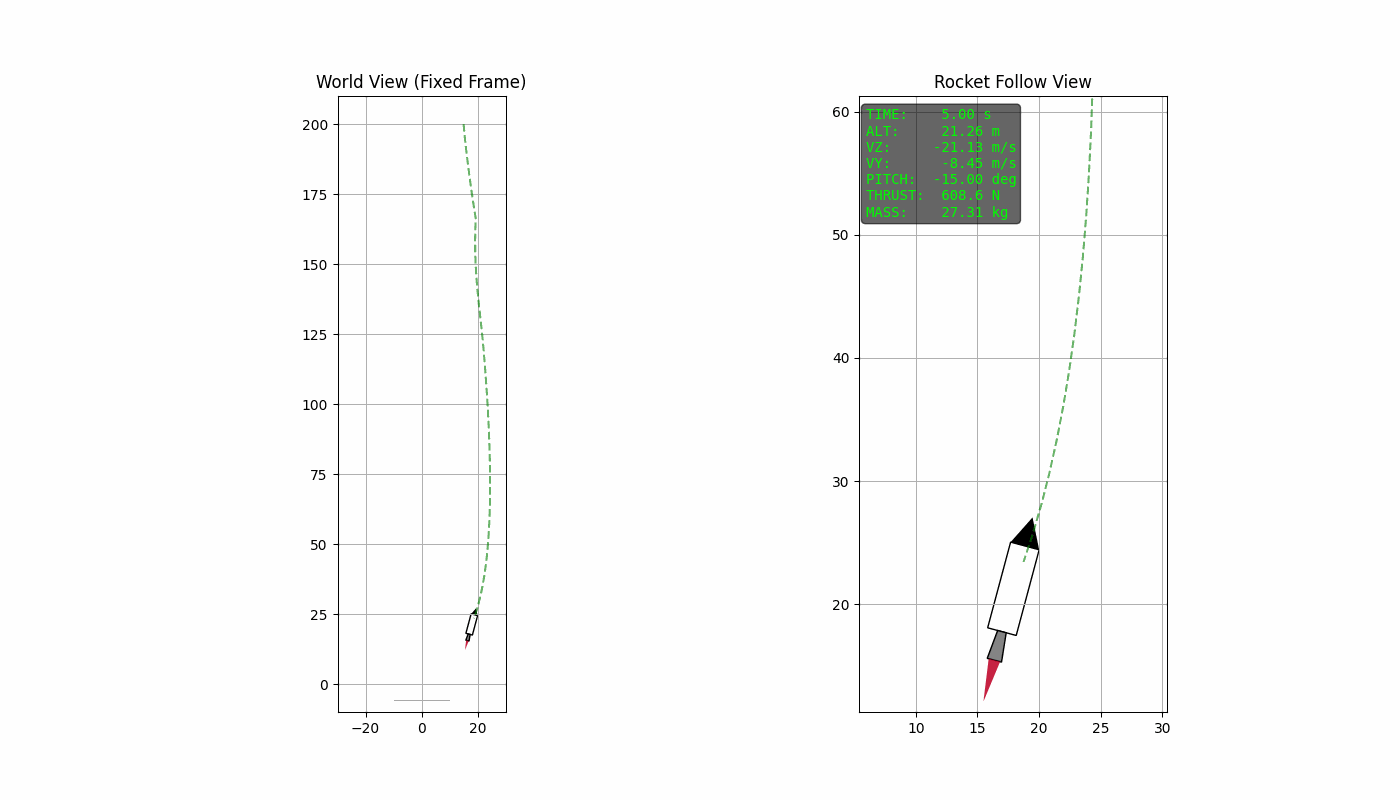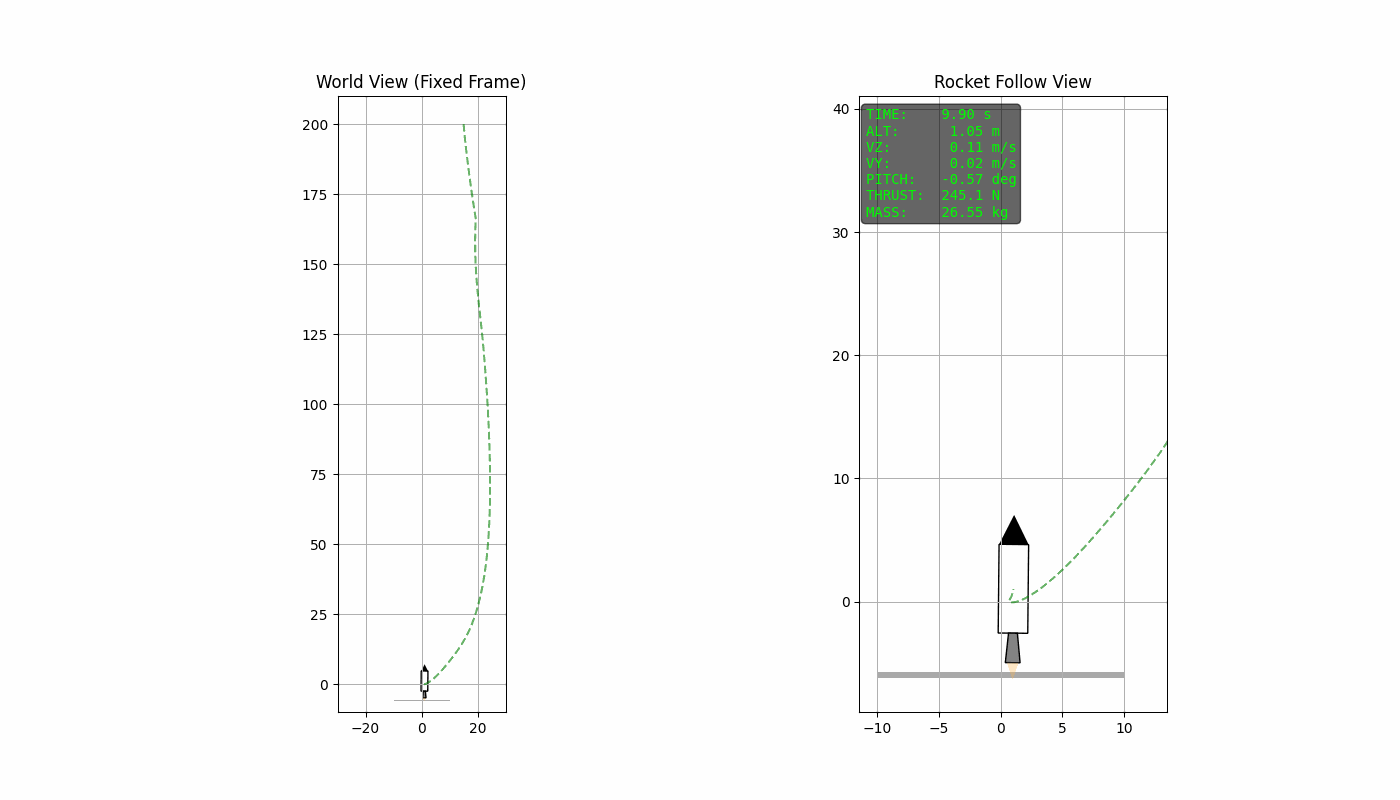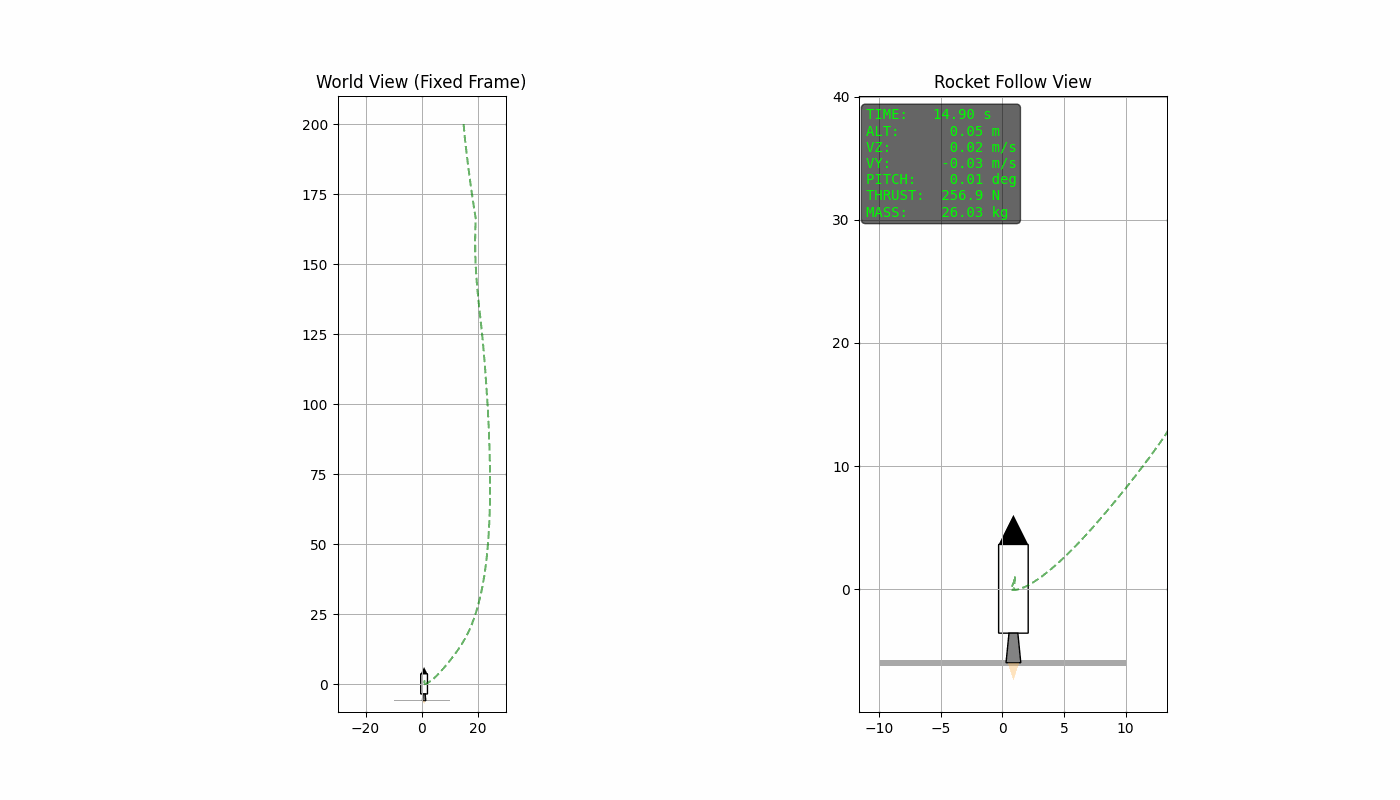
The quadratic term penalizes deviation from the desired landing state, ensuring that position, velocity, and orientation approach zero. The terminal cost enforces the accuracy in the final time step. The term penalizes large thrust magnitudes, encouraging smoother control inputs, avoiding aggressive actuation. In addition to this, the linear term directly penalizes the total thrust usage. While the quadratic term discourages large instantaneous thrust, the linear term discourages sustained thrust over time, thereby promoting fuel efficient trajectories.
With the dynamics, cost, and constraints defined, we can now state the landing task explicitly as a finite horizon optimal control problem,
subject to
Here, the mass is not directly penalized in the tracking term; fuel efficiency
is encouraged through the thrust penalty instead. Solving this problem
at each time-step, applying only the first control input, and then
repeating the procedure with the updated state yields a receding horizon
controller capable of guiding the rocket toward a soft landing while
reacting to disturbances along the way. The animation above shows the
soft-landing of the rocket using this procedure. The python-code used
to generate this animation is available
here. This toy model was inspired by the problem set in Robert Stengel's book on Optimal Control and Estimation.
Computational Implementation
Translating the continuous-time optimal control problem into code
requires a self-consistent discretization procedure. We discretize the
dynamics using a 4th-order Runge-Kutta (RK4) scheme with a time step of
s and a horizon of steps (a 4 sec look-ahead). The
resulting Nonlinear Program (NLP) is formulated using CasADi library
in python. At each time-step, the NLP is solved using IPOPT and the
solver simultaneously optimizes the physical states ,
controls and the Lagrange multipliers that ensure
and thrust
limits. To achieve real-time feasibility, we use warm starting, where
we take the optimal control sequence computed at the previous step as
the initial guess:
We shift this sequence forward by one step and duplicate the final input
to create our initial guess:
We also apply the same shift to the state trajectory and
the lagrange multipliers. This guess places the solver close to the next
optimal solution, reducing the computation time and allowing the MPC to
run dynamically in real time.
Conclusion
Model Predictive Control extends the capabilities of optimal control but with added adaptability. At every time-step, we use a model of the system to predict how the future might unfold, choose the sequence of inputs that best balances performance and effort, apply only the first input, and then repeat the process with new information. The primary advantage compared to a fixed controller obtained via an optimal control procedure is that you allow the environmental perturbations to affect the system dynamically and adapt to it with an updated controller. The rocket landing problem is only a toy example; however, the MPC framework is general enough that it is today applied in chemical industry, autonomous vehicle planning, active suspension systems, motor drives, wind turbines and wind farm clusters, and several other places.